And why it has to be treated as a development requirement
In many systems, observability fails to evolve with your system, even though it is not completely missing. It is simply incomplete.
This is rarely visible during development, and often not immediately apparent in production.
In many development environments, observability is still not treated as a real development requirement. It is something that teams intend to add later, or something that is implemented only where it seems necessary at the moment.
From a delivery perspective, this often works. Features are implemented, services are connected, and the system behaves as expected. At that stage, nothing appears to be missing.
The problem is that systems do not remain in their original state. They evolve continuously, and when observability does not evolve with them, gaps start to appear. These gaps are not immediately visible, but they become critical under the right conditions.
Subscribe to Our Newsletter
Get practical insights, case studies and learning opportunities directly to your inbox once a month.
Where things start to go wrong
- new features start relying on existing services
- previously low‑traffic components receive more load
- integrations activate functionality that was rarely used before
- business logic accumulates in places that were not designed for it
Case: when a previously minor service becomes critical
- handles a limited responsibility
- has low usage
- is not performance‑sensitive
When failure actually appears
Why this slows everything down
The broader impact
The impact of missing observability is not limited to slower technical analysis.
When the source of a problem cannot be clearly identified:
- incident resolution takes longer, increasing the duration of service degradation
- decisions are made based on incomplete information, often leading to unnecessary changes or scaling
- issues are more likely to repeat, because the underlying cause is not fully understood
- overall confidence in the system decreases, both from a technical and a business perspective
These effects are cumulative. Over time, they increase both operational cost and risk, even if the system appears stable under normal conditions.
Want to Explore This Topic Further?
Go beyond this article with our self‑paced, online training and deepen your understanding with practical insights.
Where this most often happens
The underlying issue in development
What treating observability as a requirement actually means
- structured and consistent logging that allows meaningful analysis
- basic metrics that reflect latency, error rates, and throughput
- traceability within distributed flows, so requests can be followed across services
- clear failure signals that can be used to detect issues in a reliable way
These elements are not enhancements. They are part of what makes a service complete.
If a component cannot be observed, it is only partially implemented from an operational perspective.
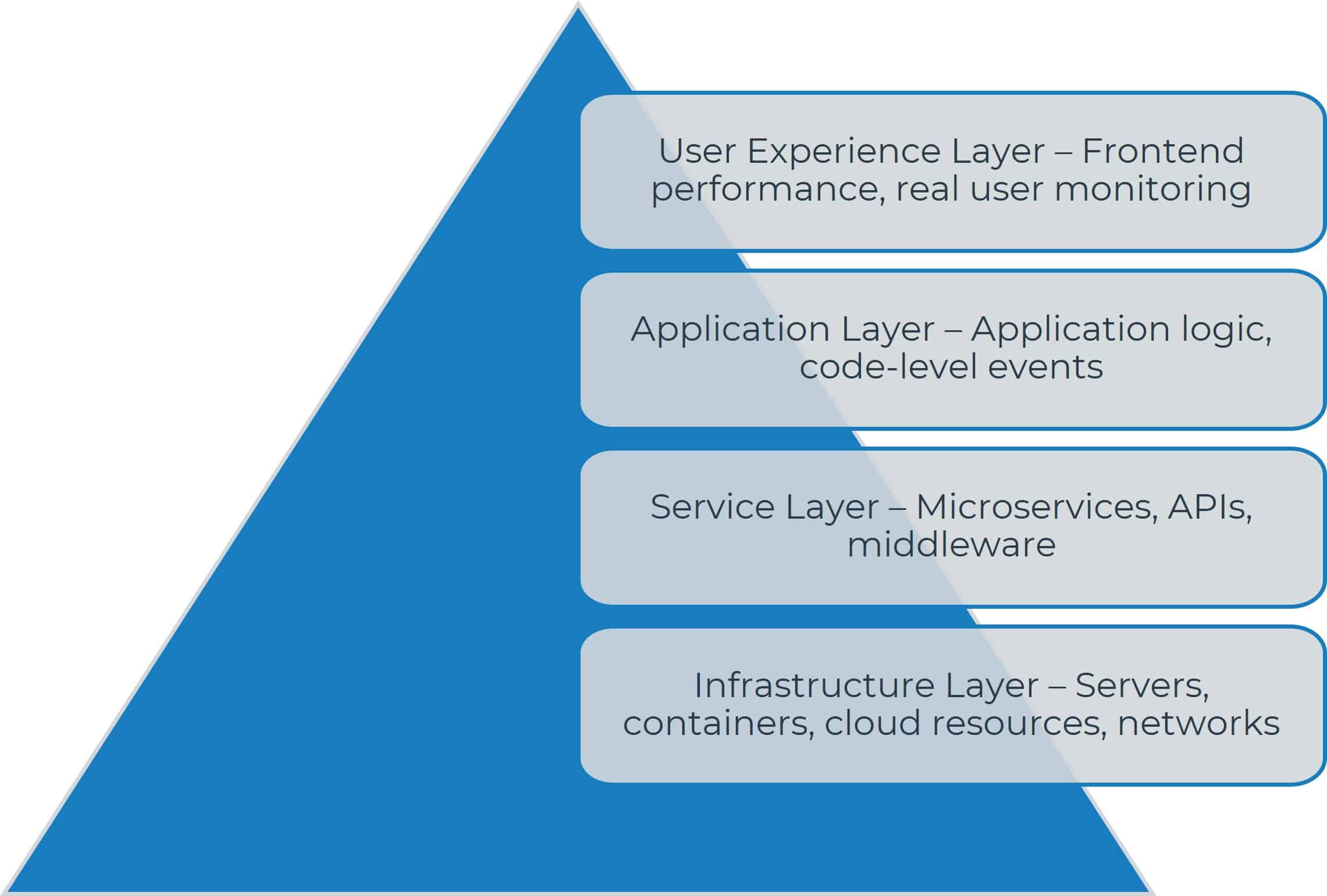
What needs to change
What this means in practice
For development teams, this requires treating observability as part of the standard definition of a service.
This typically means that:
- observability is included in acceptance criteria
- service design includes considerations on how behaviour will be measured and analysed
- existing components are reassessed when their role in the system changes
- observability is extended when services become part of critical flows
It also requires revisiting parts of the system that were implemented under different assumptions. Components that were once considered non‑critical, but have since become essential, need to be evaluated from an observability perspective as well.
Why this becomes a production risk
Missing observability does not create immediate failures. It creates conditions where failures become difficult to understand.
Final perspective
Observability does not fail by producing visible errors.
It fails by removing the ability to understand what is happening inside the system.